CERN uses ultra-compact AI models on FPGAs for real-time LHC data filtering (theopenreader.org)
261 points by TORcicada 12 hours ago
chsun 4 hours ago
One of the authors (of one of the two models, not this particular paper) here. Just a clarification, these models are *not* burned into silicon. They are trained with brutal QAT but are put onto fpgas. For axol1tl, the weights are burned in the sense that the weights are hard-wired in the fabric (i.e., shift-add instead of conventional read-muk-add cycle), but not on the raw silicon so the chip can be reprogrammed. Though, for projects like smartpixel or HG-Cal readout, there are similar ones targeting silicon (google something like "smartpixel cern", "HGCAL autoencoder" and you will find them), and I thought it was one of them when viewing the title.
Some slides with more info: https://indico.cern.ch/event/1496673/contributions/6637931/a... The approval process for a full paper is quite lengthy in the collaboration, but a more comprehensive one is coming in the following months, if everything went smoothly.
Regarding the exact algorithm: there are a few versions of the models deployed. Before v4 (when this article was written), they are slides 9-10. The model was trained as a plain VAE that is essentially a small MLP. In inference time, the decoder was stripped and the mu^2 term from the KL div was used as the loss (contributions from terms containing sigma was found to be having negliable impact on signal efficiency). In v5 we added a VICREG block before that and used the reconstruction loss instead. Everything runs in =2 clock cycles at 40MHz clock. Since v5, hls4ml-da4ml flow (https://arxiv.org/abs/2512.01463, https://arxiv.org/abs/2507.04535) was used for putting the model on FPGAs.
For CICADA, the models was trained as a VAE again, but this time distilled with supervised loss on the anomaly score on a calibration dataset. Some slides: https://indico.global/event/8004/contributions/72149/attachm... (not up-to-date, but don't know if there other newer open ones). Both student and teacher was a conventional conv-dense models, can be found in slides 14-15.
Just sell some of my works for running qat (high-granularity quantization) and doing deployment (distributed arithmetic) of NNs in the context of such applications (i.e., FPGA deployment for <1us latency), if you are interested: https://arxiv.org/abs/2405.00645 https://arxiv.org/abs/2507.04535
Happy to take any questions.
stefanpie 3 hours ago
Very cool to see you work! Early in my PhD I did some work with GNN accelerators on FPGAs (which I think later ended up in some form as a colab with some CERN or Fermilab folks) and have chatted a bit in the past with the FastML, HLS4ML, and HEP folks.
I have since pivoted a lot of my PhD work (still related the HLS and EDA). But I wonder what is the current main limitation/challenges of building these trigger systems in hardware today. For example, in my mind it seems like the EDA and tooling can be a big limitation such as reliance on commercial HLS tools which can be buggy, hard to use, and hard to debug. From experience, this makes it harder to build different optimized architectures in hardware or build co-design frameworks without having high HLS expertise or putting in a lot of extra engineering/tooling effort. Also tool runtimes make the design and debug cycle longer, especially if you are trying to DSE on post-implementation metrics since you bring in implementation tools as well.
But I might be way off here and the real challenges are with other aspects beyond the tools.
chsun 27 minutes ago
Thank you for the comment, and the questions are great.
The problems you described here are pretty much precise. In the past, and mostly now, we are replying on the commercial Vivado/Vitis HLS toolchains for the deployment of these networks through hls4ml, a template based compiler of the quantized models to the HLS projects. For this class of fully parallel (II=1) models, the tools usually give fine results, but indeed can be wrong sometimes (great recent example from our college's post: https://sioni.web.cern.ch/2026/03/24/debugging-fastml).
Tool runtime is another issue. For the models discussed in this post, they are not larger than ~30K LUTs, and with the low complexity (~dense only), synthesis time was fine. But for larger ones, like the ones here (https://arxiv.org/abs/2510.24784), it can take up to... a week for one HLS compilation while eating ~80G ram. Can get worse if time multiplex is in place things like #pragma HLS dataflow is used...
Personally, I do not usually DSE on post implementation/HLS results, since for the unrolled logic blocks, ok-ish performance model can be derived obtained w/o doing the synthesis (via ebops defined in HGQ, or better if using heuristics based on the rough cost of low level operations the design will translate to). But there are works doing DSE based on post HLS results (https://arxiv.org/pdf/2502.05850, real vitis synth), or using some other surrogate to get over the problem (e.g., https://arxiv.org/abs/2501.05515, using bops). High-level surrogate models are also being developed (https://arxiv.org/pdf/2511.05615).
We are also trying to get alternatives to the commercial HLS toolflows. For instance, I'm working on the direct to RTL codegen (da4ml) way (optionally via XLS), and the current work-in-progress is at https://github.com/calad0i/da4ml/tree/dev, if you are interested: all combinational or fully pipelined things are supported with reasonable performance model (~10% err in LUTs and ~20% err in latency), but multicycle, or stateful design generations still need a lot of manual intervention (not automated), which are to be implemented in the future. Since at some stages of the trigger chain, the system is/will be time-multiplexed, such functionality will be needed in the future.
Other works on this direction includes adding new backends to hls4ml that are oos (e.g., openhls/XLS), or other alternatives like chisel4ml (https://github.com/cs-jsi/chisel4ml). Hopefully, we will be no-longer reliant on the commercial tools till RTL for the incoming upgrade. That being said, Vivado still appears to be the only choice for the post RTL stages for us.
intoXbox 11 hours ago
They used a custom neural net with autoencoders, which contain convolutional layers. They trained it on previous experiment data.
https://arxiv.org/html/2411.19506v1
Why is it so hard to elaborate what AI algorithm / technique they integrate? Would have made this article much better
dcanelhas 10 hours ago
I'm half expecting to see "AI model" appearing as stand-in for "linear regression" at this point in the cycle.
ninjagoo 10 hours ago
> I'm half expecting to see "AI model" appearing as stand-in for "linear regression" at this point in the cycle.
Already the case with consulting companies, have seen it myself
idiotsecant 7 hours ago
blitzar 9 hours ago
I'm half expecting to see "AI model" appearing as stand-in for "if > 0" at this point in the cycle.
Foobar8568 8 hours ago
Vetch 7 hours ago
phire 10 hours ago
I'm sure I've seen basic hill climbing (and other optimisation algorithms) described as AI, and then used evidence of AI solving real-world science/engineering problems.
LiamPowell 10 hours ago
coherentpony 7 hours ago
thesz 5 hours ago
There is an HIGGS dataset [1]. As name suggest, it is designed to apply machine learning to recognize Higgs bozon.
[1] https://archive.ics.uci.edu/ml/datasets/HIGGS
In my experiments, linear regression with extended (addition of squared values) attributes is very much competitive in accuracy terms with reported MLP accuracy.
dguest 5 hours ago
yread 9 hours ago
And why not, when linear regression works, it works so well it's basically magic, better than intelligence, artificial or otherwise
plasino 8 hours ago
Having work with people who do that, I can guarantee that’s not the case. See https://ssummers.web.cern.ch/conifer/ and HSL4ML, these run BDT and CNN
Staross 8 hours ago
That works well to get around patents btw :)
etrautmann 9 hours ago
It seems like most of the implementation is FPGA, which I wouldn’t call “physically burned into silicon.” That’s quite a stretch of language
vultour 10 hours ago
Because if it’s not an LLM it’s not good for the current hype cycle. Calling everything AI makes the line go up.
danielbln 8 hours ago
LLMs also make the cynicism go up among the HN crowd.
okamiueru 5 hours ago
andersonpico 5 hours ago
fnord77 6 hours ago
Thanks for tracking this down. I too am annoyed when so-called technical articles omit the actual techniques.
jgalt212 6 hours ago
Because it does not align with LLM Uber Alles.
jurschreuder 7 hours ago
I've got news for you, everybody with a modern cpu uses this, which use a perceptron for branch prediction.
andromaton 2 hours ago
Indeed, some examples:
https://news.ycombinator.com/item?id=12340348 Neural network spotted deep inside Samsung's Galaxy S7 silicon brain (2016)
https://ieeexplore.ieee.org/document/831066 Towards a high performance neural branch predictor (1999)
archermarks 5 hours ago
I didn't know that! Do you have any references that go into more depth here? I'd be curious how the architect and train it.
isotypic 4 hours ago
I believe D. A. Jimenez and C. Lin, "Dynamic branch prediction with perceptrons" is the paper which introduced the idea. It's been significantly refined since and I'm not too familiar with modern improvements, but B. Grayson et al., "Evolution of the Samsung Exynos CPU Microarchitecture" has a section on the branch predictor design which would talk about/reference some of those modern improvements.
archermarks 3 hours ago
amelius 6 hours ago
At this point AI basically means "we didn't know how to solve the problem so we just threw a black box at it".
integralid 5 hours ago
I disagree. More often than not is "We know how to solve the problem, and the solution is some linear algebra"
Legend2440 4 hours ago
Create 2 hours ago
Other news, is that HEP has used FPGAs for L0 triggers (amongst others) for decades. These always had a diverse selection criteria in their algorithms, event filters, suppression, weights etc. And just mentioning, that some custom radhard simple readout silicon from the likes of STM isn't any news either.
And for historians: Delphi people (amongst others) had papers on Higgs selection using (A)NN from LEP data (overfit :) , obviously without the 5 sigma. It was an argument for LHC.
Dear downvoters/shadowbanners: do your homework.
serendipty01 11 hours ago
Might be related: https://www.youtube.com/watch?v=T8HT_XBGQUI (Big Data and AI at the CERN LHC by Dr. Thea Klaeboe Aarrestad)
https://www.youtube.com/watch?v=8IZwhbsjhvE (From Zettabytes to a Few Precious Events: Nanosecond AI at the Large Hadron Collider by Thea Aarrestad)
Page: https://www.scylladb.com/tech-talk/from-zettabytes-to-a-few-...
konradha 9 hours ago
How are FPGAs "bruned into silicon"? Would be news to me that there are ASICs being taped out at CERN
eqvinox 8 hours ago
CERN in fact does design custom ASICs for other things: https://indico.cern.ch/event/1115079/contributions/4693643/a...
(Probably not for this here though.)
danparsonson 8 hours ago
Could they.... have someone else do it for them?
dguest 4 hours ago
CERN doesn't build everything CERN uses:
- FPAGs like this one are generally COTS.
- All the experiments use GPUs which come straight from the vendors.
- Most of the computing isn't even on site, it's distributed around the world in various computing centers. Yes they also overflow into cloud computing but various publicly funded datacenters tend to be cheaper (or effectively "free" because they were allocated to CERN experiments).
Some very specific elements (those in the detector) need to be radiation hard and need O(microsecond) latency. These custom electronics are built all over the world by contributing national labs and universities.
CERN builds a bit.
Create 39 minutes ago
samrus 7 hours ago
Glib, but it wont be cost effective at that small scale
danparsonson 4 hours ago
quijoteuniv 11 hours ago
A bit of hype in the AI wording here. This could be called a chip with hardcoded logic obtained with machine learning
FartyMcFarter 11 hours ago
AI is not a new thing, and machine learned logic definitely counts as AI.
monkeydust 10 hours ago
For those that have experience with ML, yes. For those that have recently become acquainted with it (more on business side) they seem to really struggle with this in my experience. '
volemo 10 hours ago
Yeah, and don’t forget Eliza!
bonoboTP 6 hours ago
ML is part of AI, and has always been. AI is not equal to chatgpt and AI wasn't coined/conceived in November 2022.
killingtime74 11 hours ago
Is a LLM logic in weights derived from machine learning?
shlewis 11 hours ago
Well, yes. That's literally what it is.
dmd 11 hours ago
quijoteuniv 11 hours ago
Good one… but Is a DB query filter AI? I forgot to say though is sounds like a really cool thing to do
stingraycharles 11 hours ago
hrmtst93837 2 hours ago
Calling it "AI" is marketing sugar. It is closer to an inference-only state machine where gradient descent did the wiring instead of an engineer, and the annoying part is that once the detector setup or noise profile moves, retraining and redeploy stop being normal ML chores and turn into hardware respins, validation, and a lot of waiting. That distinction stops sounding pedantic the first time a bug fix means touching silicon instead of pushing to a repo.
Surac 10 hours ago
Very important! This is not a LLM like the ones so often called AI these days. Its a neural network in a FPGA.
duskdozer 9 hours ago
I guess shows the LLM-companies' marketing worked very well because that's what I immediately thought of.
IshKebab 10 hours ago
> FPGA
So they aren't "burned into silicon" then? The article mentions FPGAs and ASICs but it's a bit vague. I would be surprised if ASICs actually made sense here.
fecal_henge 7 hours ago
They make sense when you consider that 'on detector' electronics has all sorts of constraints that FPGAs cant compete on: Power, Density, Radiation hardness, Material budget.
armcat 9 hours ago
Not on the same extreme level, but I know that some coffee machines use a tiny CNN based model locally/embedded. There is a small super cheap camera integrated in the coffee machine, and the model does three things: (1) classifies the container type in order to select type of coffee, (2) image segmentation - to determine where the cup/hole is placed, (3) regression - to determine the volume and regulate how much coffee to pour.
porridgeraisin 13 minutes ago
The library they used (or used to use) is `hls4ml`. https://github.com/fastmachinelearning/hls4ml
I hacked on it a while back, added Comv2dTranspose support to it.
TORcicada 8 hours ago
Thanks for the thoughtful comments and links really appreciated the high-signal feedback. We've updated the article to better reflect the actual VAE-based AXOL1TL architecture (variational autoencoder for anomaly detection). Added the arXiv paper and Thea Aarrestad's talks to the Primary Sources.
dguest 4 hours ago
While you are at it:
> To meet these extreme requirements, CERN has deliberately moved away from conventional GPU or TPU-based artificial intelligence architectures.
This isn't quite right either: CERN is using more GPUs than ever. The data processing has quite a few steps and physicists are more than happy to just buy COTS GPUs and CPUs when they work.
peelslowlysee 4 hours ago
First internship, cern, summer 1989 on the opal lepc pit, wrote offline data filtering program in FORTRAN. Blast from the past.
WhyNotHugo 11 hours ago
Intuitively, I’ve always had an impression that using an analogue circuit would be feasible for neural networks (they just matrix multiplication!). These should provide instantaneous output.
Isn’t this kind of approach feasible for something so purpose-built?
elcritch 3 hours ago
incognito124 10 hours ago
You might wanna look at https://taalas.com/
lsaferite 4 hours ago
They aren't using analog circuits, are they?
Aegis_Labs 5 hours ago
This is the spirit. I'm doing something similar: scaling a 1.8T logic system using a budget mobile device as the primary node. Just hit 537 clones today. It's all about how you structure the logic, not the CPU power.
v9v 10 hours ago
Do they actually have ASICs or just FPGAs? The article seems a bit unclear.
rakel_rakel 12 hours ago
Hey Siri, show me an example of an oxymoron!
> CERN is using extremely small, custom large language models physically burned into silicon chips to perform real-time filtering of the enormous data generated by the Large Hadron Collider (LHC).
sh3rl0ck 12 hours ago
There's no mention of SLMs or LLMs, though.
> This work represents a compelling real-world demonstration of “tiny AI” — highly specialised, minimal-footprint neural networks
FPGAs for Neural Networks have been s thing since before the LLM era.
100721 12 hours ago
Huh? The first paragraph literally says they are using LLMs
> [ GENEVA, SWITZERLAND — March 28, 2026 ] — CERN is using extremely small, custom large language models physically burned into silicon chips to perform real-time filtering of the enormous data generated by the Large Hadron Collider (LHC).
SiempreViernes 11 hours ago
msla 11 hours ago
Are they some ancient small-scale integration VLSI design? Do they broadcast on a low-frequency VHF band? Face it: Oxymorons like those are part of the technical world. "VLSI" was a current term back when whole CPUs were made out of fewer transistors than we use for register files now, and "VHF" is low frequency even by commercial broadcasting standards.
rakel_rakel 11 hours ago
haha, yea they are part of it for sure, and I'm not dunking on the use of them, but I rather smile a bit when I stumble upon them.
Like (~9K) Jumbo Frames!
randomNumber7 11 hours ago
Does string theory finally make sense when we ad AI hallucinations?
konfusinomicon 3 hours ago
turns out we still needs more vibes
quantum_state 8 hours ago
This is a good one
quantum_state 8 hours ago
CERN has been doing HEP experiments for decades. What did it use before the current incarnation of AI? The AI label seems to be more marketing and superficial than substantial. It’s a bit sad that a place like CERN feels the need to make it public that it is on the bandwagon.
jeffreygoesto an hour ago
https://madoc.bib.uni-mannheim.de/809/ is one of a gazillion papers you can find with ancient technology called web search.
FarmerPotato 4 hours ago
It was ten years ago I worked on an oscilloscope for CERN with FPGA trigger. You were able to update the trigger portion of the bitstream at any time, without a reset. Typically that was a FIR filter but it could be anything.
Like anything else, once you work with a system, it gives you ten ideas where to go next...
eqvinox 8 hours ago
It doesn't say LLM anywhere.
quantum_state 8 hours ago
Good catch. Corrected. Thanks!
Janicc 10 hours ago
I think chips having a single LLM directly on them will be very common once LLMs have matured/reached a ceiling.
seydor 11 hours ago
cern has been using neural networks for decades
mentalgear 11 hours ago
That's what Groq did as well: burning the Transformer right onto a chip (I have to say I was impressed by the simplicity, but afterwards less so by their controversial Kushner/Saudi investment) .
NitpickLawyer 10 hours ago
> That's what Groq did as well: burning the Transformer right onto a chip
Are you perhaps confusing Groq with the Etched approach? IIUC Etched is the company that "burned the transformer onto a chip". Groq uses LPUs that are more generalist (they can run many transformers and some other architectures) and their speed comes from using SRAM.
nerolawa 10 hours ago
the fact that 99% of LHC data is just gone forever is insane
johngossman 6 hours ago
Not really. Think of the experiment as a very, very high speed camera. They can't store every frame, so they try to capture just the "interesting" ones. They also store some random ones that can be used later as controls or in case they realize they've missed something. That's the whole job of these various layers of algorithms: recognizing interesting frames. Sometimes a new experiment basically just changes the definition of "interesting"
Kapura 6 hours ago
Why did we stop calling this stuff machine learning again? this isn't even an llm, which has become the common bar for 'ai'
dguest 4 hours ago
Because every principle investigator in academia works in sales.
Some tried to hold out and keep calling it "ML" or just "neural networks" but eventually their colleagues start asking them why they aren't doing any AI research like the other people they read about. For a while some would say "I just say AI for the grant proposals", but it's hard to avoid buzzwords when you're writing it 3 times a day I guess.
Although note that the paper doesn't say "AI". The buzzword there is "anomaly detection" which is even weirder: somehow in collider physics it's now the preferred word for "autoencoder", even though the experiments have always thrown out 99.998% of their data with "classical" algorithms.
amelius 10 hours ago
When is the price of fabbing silicon coming down, so every SMB can do it?
IshKebab 9 hours ago
My guess would be never. The closest you can get is "multi project wafers" where you get bundled with a load of other projects. As I understand it they're on the order of $100k which is cheap, but if you actually want to design and verify a chip you're looking at at least several million in salaries and software costs. Probably more like $10m, especially if you're paying US salaries. And of course that would be for a low performance design.
I think a better question would be "when are FPGAs going to stop being so ridiculously overpriced". That feels more possible to me (but still unlikely).
fc417fc802 7 hours ago
Doesn't this vary wildly depending on the process node though? The cutting edge stuff keeps getting increasingly ridiculous meanwhile I thought you could get something like 50 nm for cheap. I also remember seeing years ago that some university had a ~micron (IIRC) process that you could order from.
aj7 2 hours ago
I wonder if it is a PhD thesis to prove that the data prefiltering doesn’t bias the results.
100721 12 hours ago
Does anyone know why they are using language models instead of a more purpose-built statistical model? My intuition is that a language model would either be overfit, or its training data would have a lot of noise unrelated to the application and significantly drive up costs.
LeoWattenberg 11 hours ago
It's not an LLM, it is a purpose built model. https://arxiv.org/html/2411.19506v1
5 years ago we would've called it a Machine Learning algorithm. 5 years before that, a Big Data algorithm.
IanCal 11 hours ago
We’ve been calling neural nets AI for decades.
> 5 years before that, a Big Data algorithm.
The DNN part? Absolutely not.
I don’t know why people feel the need for such revisionism but AI has been a field encompassing things far more basic than this for longer than most commenters have been alive.
magicalhippo 11 hours ago
t0lo 11 hours ago
i hate that we're in this linguistic soup when it comes to algorithmic intelligence now.
kevmo314 11 hours ago
This might be some journalistic confusion. If you go to the CERN documentation at https://twiki.cern.ch/twiki/bin/view/CMSPublic/AXOL1TL2025 it states
> The AXOL1TL V5 architecture comprises a VICReg-trained feature extractor stacked on top of a VAE.
dmd 11 hours ago
… they’re not? Who said they are? The article even explicitly says they’re not?
progval 9 hours ago
For 40 minutes, the article claimed they used LLMs. They changed the wording twice: https://theopenreader.org/index.php?title=Journalism:CERN_Us... and https://theopenreader.org/index.php?title=Journalism%3ACERN_...
logicallee 7 hours ago
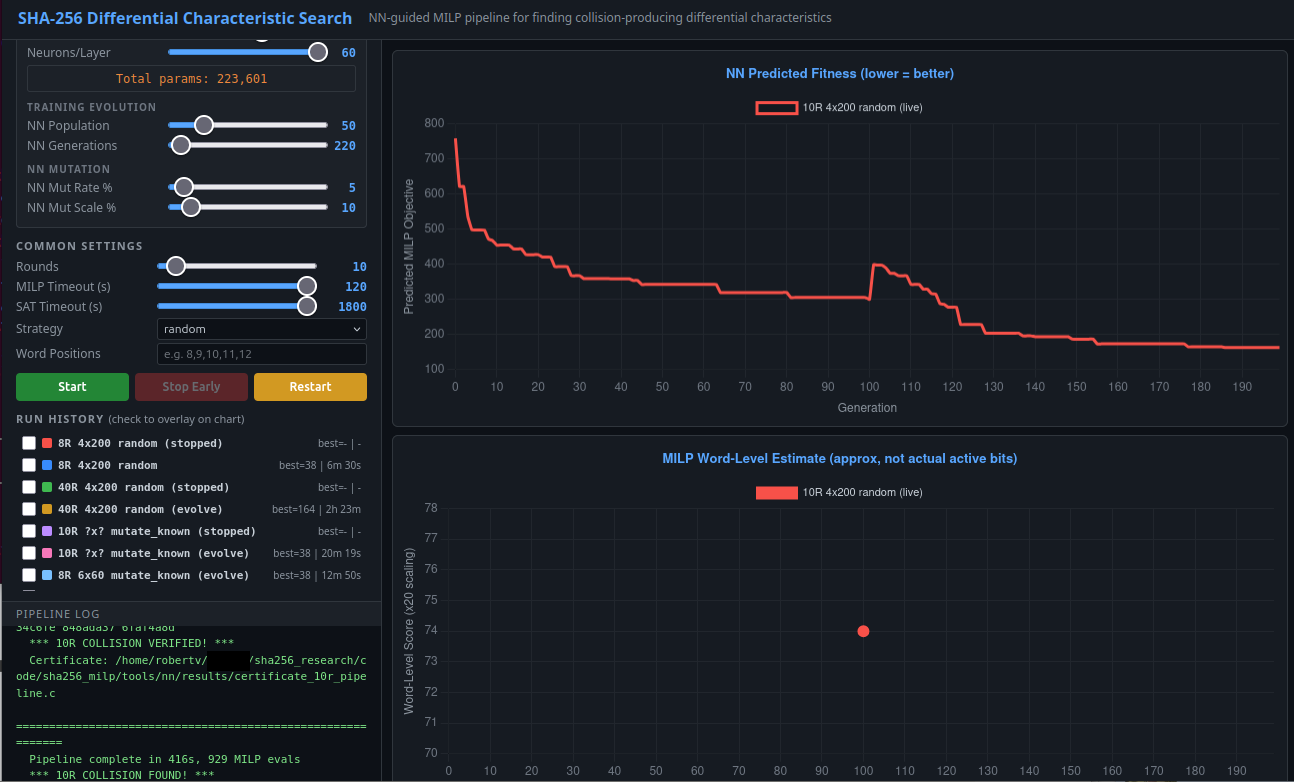
I hope they have good results and keep all the data they need, and identify all the interesting data they're looking for. I do have a cautionary tale about mini neural networks in new experiments. We recently spent a large amount of time training a mini neural network (200k parameters) to make new predictions in a very difficult domain (predicting specific trails for further round collisions in a hash function than anyone did before.) We put up a spiffy internal dashboard[1] where we could tune parameters and see how well the neural network learns the existing results. We got to r^2 of 0.85 (that is very good correlation) on the data that already existed, from other people's records and from the data we solved for previously. It showed such a nicely dropping loss function as it trained, brings tears to the eye, we were pumped to see how it performs on data it didn't see before, data that was too far out to solve for. So many parameters to tune! We thought we could beat the world record by 1 round with it (40 instead of 39 rounds), and then let the community play with it to see if they can train it even better, to predict the inputs that let us brute force 42 round collisions, or even more. We could put up a leaderboard. The possiblities were endless, all it had to do was do extrapolate some input values by one round. We'd take the rest from there with the rest of our solving instrastructure.
After training it fully, we moved on to the inference stage, trying it on the round counts we didn't have data for! It turned out ... to have zero predictive ability on data it didn't see before. This is on well-structured, sensible extrapolations for what worked at lower round counts, and what could be selected based on real algabraic correlations. This mini neural network isn't part of our pipeline now.
[1] screenshot: https://taonexus.com/publicfiles/mar2026/neural-network.png
{kind=link}