Apparently Google hates us now (twitter.com)
399 points by zeitg3ist 7 hours ago
f4stjack 4 hours ago
Google does not hate us... it is worse than that - it is indifferent to us. Hate requires some sort of recognition. I mean this single incident may not mean anything but overall google is heading to an _interesting_ place. In short, it was state of the art but in 20 years it became just another conglomerate sacrificing quality for shareholder gain, I think?
As a search engine, it does not work for me. I see promoted links above the thing I actually search for. Moved to Kagi and didn't look back.
As an AI it does not work for me. I am seeing an arbitrary usage limit, refreshing in 5 hours and a weekly quota given in a percentage. That is as opaque as it gets. Again, to give Kagi as an example I look at my usage details and I see how much is remaining in a clear way. Not working for Kagi by the way, I am just a happy customer.
As a cloud storage, it does not work for me. Probably some shared folder I am working with others has a spam user and/or a hacked account and they periodically spam x-rated notifications. And that's not only me (https://www.reddit.com/r/techsupport/comments/1azf25v/myster...). Moved to apple iCloud and done with it.
Mail is fine. After 22 years of usage, I kind of delegated it to a non-important stage in my life. The important bits have relocated to European providers anyway.
RankingMember 4 hours ago
I feel like a crazy person, but I've been using Yandex as the last resort and having positive results in finding stuff that I know is out there but Google has decided to stop letting me see. (I tried DDG but for my use it's been worse than Google).
siva7 4 hours ago
Nah you're not crazy. I also felt crazy when i discovered that some obscure censored russian search engine gives me overall better search results in 2026 than google.com
ttoinou an hour ago
pooploop64 an hour ago
ai_slop_hater an hour ago
seviu 3 hours ago
Not crazy, I always resort to yandex when I know google is not showing me the results I am looking for
DDG doesn’t click for me sadly, and I cannot point my finger to where or why
kevin_thibedeau 3 hours ago
yegg 2 hours ago
muppetman 3 hours ago
flir 3 hours ago
Someone round here said Yandex shows you what you searched for, while Google shows you what it thinks you should have searched for.
badc0ffee 2 hours ago
I found that if I search Google Maps for a specific restaurant, it assumes I must just be hungry in general. Just now, I looked for A&W and also got results for Tim Hortons, Popeyes and McDonald's.
Apple Maps never does that. Still, I usually use Google as I want an accurate idea of whether a business is actually open and what its hours are.
jorvi an hour ago
I just tried "McDonalds" and only got 50 straight McDonalds results. "Burger King" nets 23 Burger Kings, one "Spareribs King" and one "Burger Chicken King". Gotta love inconsistent experiences between customers / regions.
Also, Apple is gearing up to stuff ads (cough "sponsored results" cough) into Maps, at which point it will probably start suffering the same problem..
zx8080 an hour ago
Gmaps always zooms out when I search. No idea of that happens for others or not.
throwway120385 an hour ago
dcminter an hour ago
andoando 4 hours ago
The promoted links have gotten insane, the first 5-6 links often appear to be ads
manwe150 3 hours ago
Worse, they often aren't even relevant: we searched "passport renewal" and you had to go the the second page to even get the government site that renews passports, and not ad scams masquerading as the real thing. Optimized for engagement, presumably.
Edit: come to think of it, I don't know why I still use Google. I don't care if they track me. But when they have been actively try to prevent me from finding the information I'm looking for, and instead try to scam me?
flir 3 hours ago
BLKNSLVR 30 minutes ago
Cider9986 2 hours ago
Why don't you use an adblocker or Brave browser?
dfxm12 4 hours ago
Even after that, for whatever reason, the next tranche of links is a mixture of AI slop and shopping links. If I'm looking for information about something and not a product to buy, I often have to, gasp, go to the 2nd page of results.
aucisson_masque an hour ago
> Google doesn't work
I can relate. Just today I was working on my car and I asked Gemini how to remove the Steering ball joint. It all started well, wrote a lengthy answer and then suddenly wiped it all and instead wrote 'i can't answer that, try to ask about another subject'.
For the love of God, talking about cars are now also being forbidden by Google.
And it's not a one off, I asked multiple questions about other parts because I had a lot of issue and it was the first time removing the Gimbals and replacing the Gimbal head on that car.
Google is beyond infuriating, they are a tech company and behave like some old fashioned administration lady. Completely out of touch with real life.
On this last part, I'm convinced that it's because Google management must be completely out of touch with real life. Tech world is special, add millions on top of that..
The best that could happen to this company is to break it's monopoly so that they are forced to get rid of these lunatics.
pooploop64 an hour ago
I'm surprised it's still a standard thing to let us see the message getting typed up before it's finalized. The term "literally 1984" gets thrown around a lot but wow what a dystopian feeling when that happens. It's so much creepier than if it just said "sorry that question violates our guidelines" without showing anything.
philposting 13 minutes ago
idiotsecant 4 hours ago
The 'mail is fine' is an impending apocalypse that most people don't think too much about. Google can dump you at any time for any reason or no reason. Your chances are small, but if it happens its incredibly disruptive. I don't know the durable answer, but I definitely need to complete that step of degoogling, the job just seems huge.
yellow_postit 4 hours ago
Get a custom domain. Strat using that. Route to Gmail to start but easily decouple.
It took me about a year of updates but now I rarely get anything to a @gmail
nonfamous 2 hours ago
remarkEon 2 hours ago
Mail is terrible. The central conceit of Gmail, and unfortunately what made it immediately popular, is that you should not have to care about deleting emails because you “have enough” storage. Over time this evolved into an awful incentive structure that results in 100s if not 1000s of spam/useless/irrelevant/garbage marketing emails a day and a reminder that the next tier up is just $1 a month (for now). In the end, the state of mail is emblematic of the whole problem with that company.
hungryhobbit 6 hours ago
They're a wiki. Wiki spammers are relentless now.
Source: a small wiki I help manage, for an obscure game with <10k players, recently had to disable new signups, because the spam was so bad (and it was stuck on an old version of MediaWiki, which didn't have CAPTCHA-support).
On a popular wiki, and it sounds like this one was fairly popular, I imagine even CAPTCHA's won't be enough to stop wiki spammers. If those spammers were posting more than just "buy my penis pill" garbage (e.g. they were putting links to malware sites), Google probably, and somewhat legitimately, saw them as a source of such malware.
I imagine the fix for the OP is a thorough audit/cleansing of all malicious content on the wiki, followed by some sort of appeal to Google (which will no doubt take months, if they even respond at all, because ... Google).
Really OP's only hope is that the Google team responsible for this has an Italian Pokemon fan; otherwise they are probably screwed.
zeitg3ist 6 hours ago
We have very good anti-bot system set up with a good number of Cloudflare fine-tuned rules, limited permissions for newly created accounts, and a very dedicated team of volunteers that patrol the recent edits constantly. I cannot exclude that somewhere on a rarely visited page (out of 37k+) there is a spam link, but I doubt it’s the reason for the deindexing. I think this would also appear on the Google Search Console.
hungryhobbit 5 hours ago
I'd still recommend doing searches for common spam topics to see if you have "bad" stuff. On our wiki everything looked fine until you searched for (say) "finance" (which most users never would) ... and then you'd find a mess of spam finance stuff.
As for whether it's responsible or not, obviously I don't know. What I do know is that, without all the info, "Google saw malicious content on your wiki" is a far more logical theory than "Google just decided to hate us out of the blue".
sokoloff 4 hours ago
650REDHAIR 3 hours ago
I saw a comment on here a few days ago and the user mentioned that they use a Captcha AI bot in their day to day life because a solve costs $.003. So even if you had the captcha-enabled new version it might not have helped!
SXX 4 hours ago
If your project is popular enough to the point where tailored automation make sense there no way to fight spam really.
If its small enough you can usually avoid all the spam bots by adding any none-standard flow in registration procedure. E.g static picture or audio of something only your audience know with like drop down option to click on picture saying "I'm not a bot". Or add one more email verification for first post or edits. Or make users watch large YouTube video at certain timespamt with correct answer, etc. Anything non-standard works.
Breaks 99.9% of automation and SERP spammers wont bother create unique one for your wiki / forum / etc.
If your site is very popular you're fckd obviously and it's just arm race. This is where you can use Hashcash or something that will burn lots of CPU / GPU / RAM / etc single time so spammers will just blacklist you.
dhosek 4 hours ago
Captcha does nothing against the spammers. I have found that blocking email domains from signups works pretty well. My list is at https://www.rejectionwiki.com/index.php?title=MediaWiki:Emai... (this is a built-in feature of Media Wiki and should work ok with most versions)
anigbrowl 5 hours ago
Do you have any basis for saying that this wiki is overrun with spam, or are you just hand-waving? They were explicit in their Twitter thread about not being full of AI slop, and that they checked their list of pages that were marked as 'crawled but not indexed' and found no abuse.
I understand that you were taken aback by spam attacks on the wiki you help manage, but it's not reasonable to generalize from yours to theirs.
hungryhobbit 12 minutes ago
As I said above:
>As for whether it's responsible or not, obviously I don't know. What I do know is that, without all the info, "Google saw malicious content on your wiki" is a far more logical theory than "Google just decided to hate us out of the blue".
kstrauser 5 hours ago
AI slop wouldn’t be on my top ten list of annoying wiki spam, having been the one dealing with such things in the past. You can be free of slop and still overflowing with spam.
andrepd 5 hours ago
Weird Gloop (wiki host, started with runescape but now has dozens) has blogged about this https://weirdgloop.org/blog/clankers
righthand 6 hours ago
Social sites should have all have a tree-based invite system. This would allow wiping out spammers and their enablers in a single hit. It would allow vetting of good actors too.
ajkjk 6 hours ago
I feel like the dream solution is more like tree-based content: you see content that is vouched for by people you vouch for; if someone's account is compromised then their vouches get updated to not matter anymore, cutting their whole tree off at the root to make it invisible. Spammers should end up in largely disconnected components of the trees.
lgcmo 5 hours ago
anigbrowl 5 hours ago
xg15 an hour ago
I don't think so. "sleeper" accounts are a thing. A more sophisticated spammer could create a "high-reputation" account over some time that only posts useful info, then turn up the spam after the trust level is high enough - or even turn the tree system into a business opportunity and sell vouches to other spammers.
hombre_fatal 5 hours ago
It doesn't solve as much as it sounds.
- You can't vouch for downstream invites, so the tree aspect isn't useful.
- It's not your fault if someone's account gets taken over by a spammer.
- Just because you vouched for someone once doesn't mean you vouch for them in the future.
- What should the punishment be if you accidentally invite a bad actor?
- Your community has to be large and desirable enough for people to bother. The vast majority of sites will die before anyone cares about jumping through hoops.
Addressing issues like these ends up kinda defeating the ideals of the proposal and regresses it into a mechanic that simply makes it harder to register. Which might be useful wrt anti-spam, but it has its own issues, like people having to constantly grovel for invites, shutting out earnest contributors, etc.
awesome_dude 4 hours ago
Sayrus 6 hours ago
You still need criteria to handle reputation: does an account invited years ago and now spamming affects the reputation of the inviter, how much? What about the hacked accounts?
For small platforms it makes a lot of sense, for larger the potential for abuse is still there in different forms.
WarmWash 6 hours ago
Now you just created a market for farmed "legit" accounts.
dantillberg 5 hours ago
awesome_dude 4 hours ago
charliebwrites 6 hours ago
That’s literally how Facebook started
I remember begging my older step brother for an invite since he had the college email to get in
phil21 4 hours ago
Then it’s just hacked account whack-a-mole and deciding who legitimately got their account hacked and who is lying.
It raises the bar at least somewhat though!
CalRobert 6 hours ago
Interesting to compare this site and lobste.rs for that
threecheese 6 hours ago
righthand 5 hours ago
danaris 4 hours ago
How old a version? I've been running a much more obscure game (<150 players, down from ~1k in 2010) for some time, and it was using QuestyCaptcha back in...2008 or so, I think? Certainly at least 15 years ago. It's almost always been sufficient: just put in a couple of questions based on knowledge of the game itself.
snovv_crash 3 hours ago
Also running a wiki. Similar. Had a sign-up based on in-game knowledge. LLMs now crack it and I had to turn off signups about a year ago. Now people email me directly if they want an account.
teaearlgraycold 6 hours ago
An organization I'm involved with has had to add Anubis (https://github.com/TecharoHQ/anubis) because of the recent wiki attacks from LLM scrapers. It's finally fixed our outages.
marginalia_nu 6 hours ago
To be honest it's probably just jank on Google's end.
There's a lot of delayed cause and effect in search, and it's much easier to make a minor mistake that excludes 0.1% of websites from crawling or indexing than it is to detect that it's happened except from affected websites telling you about it.
Like in marginalia I've had a bug that affected websites in the condition that if the root path didn't support HEAD, but did support GET with a `Range` header, and it correctly responded with a HTTP 206, then the website wouldn't be indexed because some code that was testing the root document for issues as an initial probe handled that as an error state. Most websites that support range requests also support HEAD (as this usually means the document isn't generated). Except a handful of Caddy-based configurations, about 0.3% of servers.
nitwit005 3 hours ago
Or just some AI flagging it as some sort of content they don't want to show. There's no way they can be perfect at that.
bradleykingz 4 hours ago
from 511k indexed paged to just 11? that is some serious jank
marginalia_nu 4 hours ago
From the perspective of a web search engine indexing tens to hundreds of billions of documents 500k docs is not very noticeable.
phyzix5761 6 hours ago
Why would Google need to direct traffic to the website when they've already scraped and trained their models on the data? Content creators and legitimate websites were wham-bammed and thank-you-ma’amed.
twodave 5 hours ago
Personifying Google in this way is not realistic. The search team alone at Google is made of thousands of people who are all working on different things with an over-arching mission of making the web MORE accessible, not less. Any release from any of those people could have created a side effect of this kind. Is there a chance it was an intentional policy implementation? Sure. But the odds are heavily against it.
ravenstine 5 hours ago
This seems akin to saying that humans shouldn't be personified because their brains are made of millions of neurons that are all doing different things. But the actions or motives of individual processing units are hardly relevant, especially at the scale of The Google. We don't need to speculate how non-malevolent individuals cause harmful side effects. It doesn't even matter what The Google "thinks". The system is what it does, and what it does is consistently operate in ways that are not for the mere benefit of users of the Web. The conceptual model that The Google hates (or is callously indifferent to) us makes far better predictions than a model presuming thousands of people make mistakes while trying to make the Web more accessible. It doesn't matter if the former model isn't a technically perfect reflection of reality. We are less likely to be victim to The Google when we act as if it is a hostile force. Diffusing the results of its actions across thousands of nameless humans increases the risk that one finds themself posting on HN or X about how The Google spontaneously locked them out of their entire life.
mrweasel 4 hours ago
Someone at Google are ultimately responsible for the overall direction. Saying that a company is made up by thousands of people and they should be judge, perhaps not individually, but at least not as one gigant whole, is asking the employees to absorb moral responsibility, while the corporate is excused of any wrong doing.
twodave 12 minutes ago
bartekpacia 4 hours ago
Is this irony? Cause there’s no way anyone believes these “we want to make the world a better place” cliches anymore lol
aleqs 3 hours ago
> over-arching mission of making the web MORE accessible, not less
Right, that's why they pushed AMP and upranked AMP pages in their results. That's also why they decided to severely neuter/remove as blocking extensions for Chrome. That's also probably why google search results are getting worse by the month with more and more ads and spam being upranked to the top.
It's because google has a mission of making the web more accessible. Okay bud.
elphinstone 4 hours ago
It's laughable to assume good intentions at this point, this predatory monopolist makes every decision against a free and open internet and in favor of monetization, authoritarianism, and enshittification.
croes 4 hours ago
The over arching mission is to make profit.
And accessibility was meant for Google so they can collect all the data to make even more profit.
insane_dreamer 2 hours ago
sweet summer child,
> thousands of people who are all working on different things
those thousands of people aren't making the overall decisions
> with an over-arching mission of making the web MORE accessible
google's mission has for a long time now been to deliver value to its shareholders; making the web more accessible is secondary, nice if aligned with increasing revenue
mlinhares 5 hours ago
lol.
hmokiguess 3 hours ago
I thought the same, isn’t a lot of this data stable and static. Why recrawl and continually index stuff that has low value if the corpus is already feature complete.
caminanteblanco 5 hours ago
I was listening to David Bowie's Suffragette City as I read your comment (Apparently Bowie was a popularizer of 'wham bam, tym' usage)
WarmWash 6 hours ago
>wham-bammed and thank-you-ma’amed.
So same thing ad-block users have been doing for 20 years now?
Edit: You can downvote, but you can't tell me the difference, can you?
Edit 2: Funny how when you call out ad block users for denying creators revenue, they go on about how the internet was fine in '96, how no one should expect anything for putting content online, or how it's their computer so they can chose what loads on it. Where did those arguments go?
pbhjpbhj 5 hours ago
Users take part and improve wikis, it's the whole model. If they don't take the adverts, they still can contribute. Googlebot isn't making edits, not even giving signal to the site about what is useful allowing the owners to hone the site.
Two ways in which issues who have adblock are better than bots.
Users will promote organically, which can win more credence than even a higher listing in SERPs. Depends if your wiki is part of building a community.
WarmWash 5 hours ago
aleqs 3 hours ago
What bizarre and absurd line of reasoning. Users who care about their privacy and opt out of downloading ads and malware are 'denying creators revenue'?
Are you denying creators revenue by not reading reading/observing every ad that comes your way and making purchases based on them? Maybe you should read/comment on HN less and focus on consuming more ads instead?
What at an incredibly stupid thing to say.
WarmWash 3 hours ago
interloxia 5 hours ago
Users, ad-block users, and scrapers all consume the publicly-available content whether you like it or not.
I expect the difference is that the scrapers are the most likely to regurgitate the content one way or the other.
anigbrowl 5 hours ago
The difference is that I am not preventing anyone else from finding their content. I whitelist ads on sites that have good ad policies, like limiting ad size, labeling ads, and not allowing animated ads.
Advertisers only care about attention, if you don't impose editorial standards they'll contaminate your entire site.
WarmWash 5 hours ago
nehal3m 5 hours ago
If there is any model on the internet that has proven you don't need to monetize through ads for a working business model, it's Wikipedia.
hirako2000 4 hours ago
pessimizer 4 hours ago
> So same thing ad-block users have been doing for 20 years now?
Ad-block users didn't mine Pokémon Central for content, then remove them from search listings. Changing the specific criticism made to the generic "denying creators revenue" is a distortion, because they screwed over all people who wanted visitors, not just the people who wanted visitors to milk them for cash.
If I made a forum about trains because I wanted people to come to the forum to talk about trains, Google milked the forum for all of the accumulated information about trains, then made it impossible to attract new users to talk about trains.
bryanrasmussen 5 hours ago
well I didn't downvote but there is an obvious difference in thousands of uncoordinated people doing something whenever it benefits vs. a large organization with automated resources doing things at the kinds of speeds and volumes that automation allows.
themafia 5 hours ago
You can run unblockable ads on your site.
You just have to not use third party integrations that run untrusted code on your visitors computers.
Forgeties79 5 hours ago
The edits are likely why you’re getting downvoted so much tbh.
WarmWash 4 hours ago
p4bl0 6 hours ago
The same thing happened with my blog a few weeks ago. It was well referenced for years and suddenly almost all of my entries are not indexed anymore. The Search Console indicates that the URLs were crawled but are currently not indexed, and contrary to technical problems, there nothing I can do to fix it, I just have to accept that most of my articles cannot be found via Google anymore.
EDIT: I don't actually think it is related, but now that I think of it, the timing corresponds with when I started setting up TDMRep to forbid using my content to train LLMs.
judah 6 hours ago
Same. I've been running a personal blog for over 20 years. Last year, I couldn't find any links to my blog on Google. Went to Google Search Console to find all my links are "Crawled by not indexed", with no reason given.
pbhjpbhj 5 hours ago
If Google already slurped up any training data from your site, then not indexing it probably gives them something of a moat over anyone using Google search for site discovery.
atleastoptimal 36 minutes ago
I think people were fooled by the 2000s-2010s tech propaganda that the tech/internet companies in general were some sort of utopian benign benefactors of humanity.
All businesses seek to survive, and will use human goodwill until it is not needed anymore. Everyone who thought that Google was opening up the web out of the generosity of their hearts will be shocked when they "feel" nothing when that is taken, because ultimately a company cannot "feel" anything at all, so the OP headline is a silly proposition.
tomp 3 hours ago
FYI Google also hates OpenCV
What used to be easily searchable (e.g. "opencv orb") now brings up pages and pages of spam sites (basically "learn opencv here!" blogspam).
Literally the first result on "docs.opencv.org" is on page 4, and points to version 3.4 (9 years old!).
The page that I want https://docs.opencv.org/4.13.0/dc/dc3/tutorial_py_matcher.ht... is nowhere to be found.
rolandog 2 hours ago
I think the reading has been on the wall for some time for products that are not subscriber-funded due to enshittification. We should vote with our money and switch to better products that are customer-oriented and not advertiser-oriented.
Growing up as a teenager and young adult, I remember fondly browsing Newgrounds and being thankful to those who were paying to keep the servers running; I swore that once I got my footing and had some cash to spare, I'd be paying it forward and have been doing so for almost ten years now (took me longer than expected).
So, what I'm trying to encourage is to normalize THAT (Having X% amount of paying customers that make it possible to keep it free for those who can't pay, or to support growth), because I'm pretty sure dozens of thousands of successful careers in programming and animation were launched — or at least inspired — by wonderful sites like Newgrounds and I think that has been very much a positive net thing for society.
paol_taja 6 hours ago
You guys made the classic SEO mistake of building a real community site instead of a Reddit thread, a coupon subfolder, or an AI summary.
Scherzi a parte, spero che possiate recuperare presto…
zeitg3ist 6 hours ago
Grazie! Speriamo anche noi.
frouge 6 hours ago
I can even tell you that Google hates us all
georgemcbay 6 hours ago
Google neither hates nor loves any of us, the only thing it cares about as an institution is cramming as many advertisements in front of as many people as it can get away with to generate increasingly ridiculous piles of money.
This is not meant to be a defense of Google, which is (like virtually every large corporation) completely sociopathic.
EvanAnderson 6 hours ago
Public corporations have historically been multi-cellular biological organisms made up of individual cells working toward the collective goal of continuing the organism's existence. They're probably most analogous to bee hives.
Each cell receives nourishment from the corporation in the form of monetary compensation (and other benefits). Some cells have a more direct role in the "reasoning" process of the organism than others, depending on their logical position within the corporation.
The corporations aren't sentient in the collective, though it can be argued many of their constituent cells are. The corporations are able to influence their environment using individual constituent cells to communicate with similar cells in other organisms.
Ultimately, the corporation itself has the goal of producing value for its owners, since its owners provide the working capital necessary for the corporation to function.
The methods corporations use to achieve their goal of returning value can be opaque to the owners and potentially inscrutable to the individual constituent cells. Their "reasoning" is a manifest property coming from the interaction of the cells with the environment, the cells interacting with each other (both within and outside the corporation), and other organisms.
(There's the neat rub that individual cells can be constituents of multiple organisms simultaneously, too!)
If the owners stop receiving value and withdraw their working capital the corporation becomes unable to nourish its cells and it dies.
Recently these organisms have become biological / technological hybrids, incorporating unconscious computational models in their reasoning process. This change increases the inscrutability and opacity of the reasoning process. It's likely the unconscious computational models will eventually be tasked with communicating with similar models in other organisms, at which point the inscrutability will probably increase by an even greater amount.
It's going to be interesting when the corporations, talking with other corporations, manifestly decide that they don't need human components anymore. All of that can happen without the pesky need for consciousness, too.
themafia 5 hours ago
fredley 5 hours ago
Increasingly I see marketing as akin to LLM training. We are all being trained (by activating and reinforcing neural pathways in our meaty heads) to respond to certain stimuli in a certain way (e.g.: at the store, select _this_ brand of soap).
bigstrat2003 6 hours ago
Don't make the mistake of anthropomorphizing Google, as a wise man once said.
logicchains 6 hours ago
All large companies are sociopaths, but few tech companies treat their paying customers with the level of contempt that Google does.
xp84 6 hours ago
pbhjpbhj 5 hours ago
chakintosh 5 hours ago
After yesterday's keynote and the changes to Search, it became clear in the near future, Google will cease to direct any traffic to websites and the search results will just become a footnote in Gemini's response.
arjie 6 hours ago
Wikis are just high-risk for SEO. Getting my own personal wiki to be indexed was such a challenge that I'd just about given up when a friend who is more acquainted with the whole thing helped me make sure I had all the bits and bobs in the right place. If you're not careful, people can easily put spam all over your site and then it'll really ruin your presence on a search engine.
Google is really big, though. Really really big. They're so big that not even all the people inside Google are trustworthy to them on a subject like this.
But they don't universally hate wikis and so on. It's just you have to do a lot of work and make sure you don't have spam on your wiki, and then fill in all of the information in your meta tags, and have a sitemap.xml, and all that. Here's my wiki for example: https://wiki.roshangeorge.dev/w/images/8/89/Screenshot_-_Goo...
{kind=link}
rglover 5 hours ago
Tangential: this would be an excellent time for the Kagi folks to do a Mullvad style campaign around "Remember Google before the apocalypse? Meet Kagi."
Mickelby 2 hours ago
It's hard to over-estimate the "crawled but not currently indexed" apocalypse that's happening at the moment.
Google is DRASTICALLY reducing the size of their search index. The reasons can be debated but the outcome is clear. A much smaller index of pages they consider to be the primary authority. Anything else they are not interested in and do not need.
_alphageek 5 hours ago
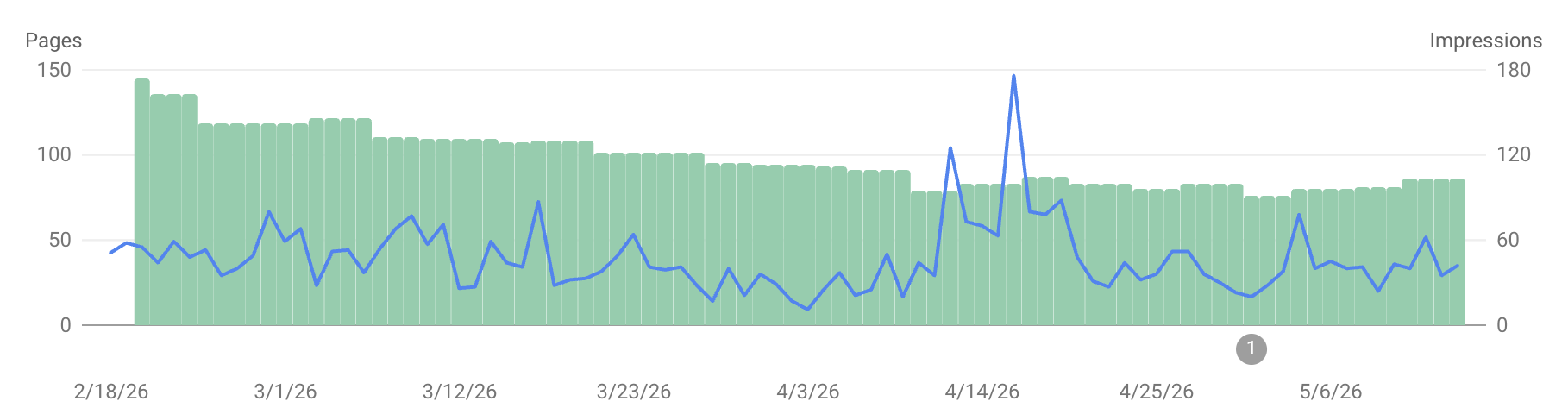
I still have 42k page indexed, but previously I had 20k impressions per day, past week impressions started to change. And now I have 399 impressions per 24 hours :/
OsrsNeedsf2P 2 hours ago
This happened to an open source project I used to maintain[0]. After years of healthy growth, traffic dropped 95%. No explanation. It then restarted to organically grow again. It's been about 3 years, and we're still get roughly 40% of the hits we used to, but we were set back about 6 years of natural growth.
computomatic 6 hours ago
A wiki with only 11 pages?
Perhaps they will investigate why 541,000 pages aren’t being indexed. In my experience, Google provides adequate tools for identifying and resolving indexing issues.
Google won’t serve pages it hasn’t indexed. Seems they left a lot of relevant details out of that tweet.
Edit: and the most likely answer would be that their current robots.txt disallows virtually all indexing. I’m no SEO expert but entries like this seem like footguns:
User-agent: Google-Extended
Disallow: /
zeitg3ist 6 hours ago
In the first image you can see how indexed pages go from 40k+ to 11 in the matter of days. Further down the thread I show how 114k+ pages are marked as “crawled but not index” and we can’t understand why. The rest is stuff that is (correctly) blocked by robots.txt.
ZeWaka 5 hours ago
Interesting. My small game wiki was also affected ~3 weeks ago. It doesn't even show up on Google anymore even if you directly search for the URL.
We don't get any spam since there's no public signups for editing access.
bradleykingz 4 hours ago
interesting indeed. very short sighted by google if so. before, the incentive for publishing on google was discovery... if that goes away, then what?
clacker-o-matic 7 hours ago
oof that sucks; i really wish there was more info on why google decides to crawl or not crawl a page
hackerbeat 5 hours ago
They sucked out all the content and then pulled the plug.
declan_roberts 5 hours ago
I suspect this is a cloudflare thing since the other search engines are doing fine. I'd look closer into your cloudflare settings and see what you can relax.
Aboutplants 4 hours ago
Google does not hate you, they simply do not care about you at all. There is a very minor difference
MintPaw 4 hours ago
I'm not sure about that, they could do far worse than delist you if they really hated you.
astkl 6 hours ago
My guess is that the combination of Wiki and Pokemon is highly suspect for Google.
The Pokemon Industrial Complex has advanced astroturfing especially on YouTube/Twitch, where streamers mention the damn things in any second episode, they "accidentally" meet people going to Pokemon conventions in live streams and so on.
Try to audit the Wiki if anyone abused it.
stronglikedan 4 hours ago
Content creators need to accept that traditional SEO is a thing of the past, because traditional search engines are a thing of the past. None of my normie friends use search engines any longer. They just ask the AI - anything and everything - the AI has all the answers they need. The best that any content creators can hope for in terms of engagement is that they were the quoted source and the user cares enough to check sources. Content creators just need to find new ways of driving engagement now, and we're never going back so there's no use crying about it.
Galanwe 4 hours ago
Well LLMs are trained on text influenced by SEO, and they use search tools also weighted by SEO. So SEO is not irrelevant I guess ?
j2kun 4 hours ago
Public pressure campaigns work on companies, and this situation is thanks to Google.
anigbrowl 5 hours ago
One of the sad things about this story is that everyone has to read tea leaves to guess what reasoning might be going on at Google's end. Tech companies have normalized the practice of cutting people off with no explanation, or saying 'we investigated and found a violation' without articulating what the violation is. Naturally, they want to secure themselves against abuse and people trying to game their system, but refusing to provide any information does not achieve that.
It does infuriate legitimate users, enables other kind of abuse and scamming (eg immunize yourself against delisting with this one weird trick!', link farming etc), and act as a fig leaf for abusive behavior by platform operators. Effectively, we've allowed large teach companies to act as digital dictatorships with no accountability to their customers. Yes I consider users to be 'customers' even if they're uploading content or doing searches 'for free'. If you're monetizing their activity on your platform, they are your customers whether or not you call them that to avoid legal liability.
Jiro 4 hours ago
They're a private company, they can ban whoever they want.
Or at least that's what I heard a few years ago when it was politically incorrect people complaining about being banned with no accountability. They're a private company, it's their servers. You may not even be paying anything. So they can do anything they want to you and you have no cause for complaint.
sitebolts 6 hours ago
Google's always adjusting its search rankings, but it's rare for a legitimate site to suffer such a sudden massive hit without reason.
My first thought would be that they accidentally blocked Google's crawler (maybe through some kind of anti-AI setting?) or that Google believes that the site is serving malware or spam. Either scenario can have that kind of effect. I can see that their forum at least appears to have strong Cloudflare anti-bot rules in place, so that might be the case.
They're also using a subdomain for both their wiki and forum, which Google has been observed to punish. They might consider moving each of those to their own separate .com domain.
But aside from that usual stuff, there's one more possible reason that's specific to this site. In November of last year, the Pokemon Company rebranded their "Pokemon Trainer Club" to "Pokemon Trainer Central", which is the first result that comes up when you search for "Pokemon Central".
That change was made a few months before the sudden drop in traffic, but could still be a viable explanation here. Google does routine re-ranking on a daily basis along with occasional major re-ranking, which happens maybe a few times a year, so the delayed hit that they saw could have come from Google finally recognizing that most people who search for "Pokemon Central" are no longer looking for the wiki like was once true in the past.
https://gonintendo.com/contents/54863-pokemon-trainer-club-r...
zeitg3ist 5 hours ago
A blocked Googlebot would’ve caused a report of 403s in the Search Console, which isn’t the case. And the subdomain has worked perfectly fine for the last 15 years.
You may have a point with the Trainer Central rebranding, but please consider this in the context of Italian language results. It’s not about reaching the home of the wiki (which is pretty much the only page that’s still indexed), it’s all the other search queries (Pokémon names, moves, games, etc - without adding “pokemon central” even) that usually returned our wiki’s dedicated page as first result (or top 5 at least) and now those specific pages are not even indexed anymore.
0x5FC3 5 hours ago
> They're also using a subdomain for both their wiki and forum, which Google has been observed to punish. They might consider moving each of those to their own separate .com domain.
Any sources for this? AFAIK, Google treats websites on a subdomain as a separate entity.
jolmg 5 hours ago
https://developers.google.com/search/docs/fundamentals/seo-s...
> Things we believe you shouldn't focus on: As SEO has evolved, so have the ideas and practices (and at times, misconceptions) related to it. What was considered best practice or top priority in the past may no longer be relevant or effective due to the way search engines (and the internet) have developed over time.
> Subdomains versus subdirectories: From a business point of view, do whatever makes sense for your business. For example, it might be easier to manage the site if it's segmented by subdirectories, but other times it might make sense to partition topics into subdomains, depending on your site's topic or industry.
Doesn't quite explicitly say it treats them the same, but it kinda implies it.
pbhjpbhj 5 hours ago
drcongo 7 hours ago
scrollop 6 hours ago
Thank you
pcdavid 6 hours ago
This might be useful: https://addons.mozilla.org/fr/firefox/addon/toxcancel (Redirects to xcancel.com (a mirror of x) when the browser is about to load an x.com page).
kokojambo 6 hours ago
It appears for me when I search for it. Even Gemini is cool with looking for it.
Here is a part of the Gemini result I got which was directly above the regular result link.
"Pokémon Central is a major community network and independent Italian encyclopedia for everything Pokémon-related"
Honestly, the title is super clickbait and it doesn't even reflect reality. Its so easy picking some giant entity far away and create some drama about it. Dont get me wrong, I am not a google fan, but I also dislike clickbaits and whiney dramatic claims, moreover if unverified.
zeitg3ist 5 hours ago
Maybe the claims in the Twitter thread weren’t clear enough; I’ve added some clarification especially for you: https://x.com/pokemoncentral/status/2057157781611024764
kokojambo 5 hours ago
Thanks for the clarification, the title is still a whiney clickbait.
hamdingers 6 hours ago
Do you suspect they have faked the search console screenshots as well? Make your accusation explicit.
opengrass 4 hours ago
Easily a legal request.
startpage_com 4 hours ago
Why not use startpage.com which is doing anonymous searches in google?
bradleykingz 4 hours ago
default vivaldi engine. no complaints.
cynicalsecurity 6 hours ago
Can someone start a new Google, please? Just search, nothing more. I'm willing to pay 10 USD a month for that. API access included.
CharlesW 6 hours ago
mghackerlady 5 hours ago
I think it's become increasingly clear that search engines, in their most basic form, aren't cut out for the internet of today. The open internet is basically dead and I see the world returning to old yahoo-like web page indexes that are manually verified and sorted
elaus 5 hours ago
Kagi has been mentioned already, just to provide anecdotal reference: searching for "pokemon wiki" with the country set to Italy shows OP's website as first result.
kevincrane 6 hours ago
Yeah Kagi already exists luckily, it’s extremely good and worth the money.
PLenz 5 hours ago
Now? Google has hated us since at least the DoubleClick aquistion in 2008. That's when people became the product
cess11 6 hours ago
Perhaps they're decommissioning search in favor of LLM:s.
CodesInChaos 6 hours ago
That's only supposed to happen later this week.
arikrahman 6 hours ago
This aligns with their Google Zero doctrine, keep all info internal and make the goal for the user to hit 0 external websites.
echelon 7 hours ago
Pokemon Central runs ads (Google AdSense at that!), which is probably how they pay for everything.
Google is likely their biggest inbound source of traffic, so they're probably experiencing a marked revenue drop as well.
It's unfortunate that so many livelihoods are subject to the capricious whims of a single company. A company that is increasingly seeking to keep users on their engine without sending eyeballs or revenue to any third parties at all.
We're watching Google's "embrace-extend-extinguish" arc for the web. It's not over by a long shot, but they absolutely intend to finish the job.
vrganj 6 hours ago
Hi EU. How about one of those lovely anti-trust cases?
skeptic_ai 6 hours ago
I really hope eu can extinguish Google before they extinguish all websites. Will be an exponential death of website very soon once they lose traffic.
vrganj 5 hours ago
spiderfarmer 6 hours ago
It’s why I moved to in-house advertising. It’s a lot of work, but I hope it is the right decision.
righthand 6 hours ago
Why is it a lot of work? Could you specify some off the more difficult effort? Wouldn’t LLMs help speed this up? This is the one area where I’d think Llms could really take Google down by empowering in house ad platforms.
dylan604 6 hours ago
pkaye 6 hours ago
Its better off if ads go away. Just use ad blockers.
zeitg3ist 6 hours ago
We would like the wiki to be free of ads, but hosting costs at our scale are real. Since we don’t like ads either, we compromise like this: users can register for free and never see an ad (they are only served to anonymous visitors); they can also use an ad blocker and we won’t bug them about it.
rolph 5 hours ago
ChrisArchitect 6 hours ago
Title could be: Apparently Google hates Pokémon Central Wiki now
(to be clearer what the source of the post is)
m4tthumphrey 6 hours ago
No, I think "us" is apt, considering this will eventually affect all sites that rely on traffic from Google search, which is basically every text heavy site.
All we can hope for is that people will stop using search (after eventually having enough of the AI wave) for these sort of niche sites and will bookmark and access them directly in future. I don't have much hope.
xp84 6 hours ago
I spend a lot of time wondering about the true role of search in people's lives in 2026. When I watch people use the Internet, it seems like most of them perform searches simply as fuzzy-matching navigation to the websites they use. Like the way many people use Spotlight to launch desktop apps.
I think this is because
(A) bookmarks lists are inconvenient - scrolling to find a bookmark is slower than typing "youtube" or (cringe) "bank of america" in the URL bar
(B) typing URLs directly requires precision of memory with TLDs being numerous and even things that were once predictable are now mere suggestions (e.g. is your city or town at cityofwhatever.com? city.org? city.gov? Could be anything!)
(C) related to (B) if you screw up a full URL you may well end up at a phishing site that looks like the site you wanted.
I really believe that 90% of Google and Bing searches today are probably for the names (or misspelled or partial names) of the top 100 websites.
If the dominant browsers weren't Google Chrome and Mobile Safari (who gets paid by Google for every search) browsers would build bookmarks for you of your frequently-used sites, and ordered by frequency of visits, present those for direct navigation when you type a word in the search bar, and not send any query to a search engine if you chose one of those. But all incentives point very strongly against doing that and toward sending you to a SERP with 13 ads and an "AI Overview" above the organic results.